Psychologie expérimentale : CM n°9-10&11
L’accès au lexique
Lexique et accès au lexique :
Lexique :
Approche linguistique :
« Comme terme linguistique général, le mot lexique désigne l’ensemble des unités formant la langue d’une communauté, d’une activité humaine, d’un locuteur etc. ». Selon Rey-Debove (1975), ces unités lexicales peuvent être plus ou moins complexes :
- Morphème (monème pour Martinet) : plus petite unité ayant une signification qui peut être libre ou non (c'est-à-dire qu’on ne les trouvent pas seuls dans la langue : les suffixes par exemple).
- Combinaison de morphèmes / monèmes.
- Lexies ou expressions.
Le terme « lexique » est généralement réservé aux unités de classe ouverte, c'est-à-dire aux unités significatives non essentiellement grammaticales (noms, adjectifs, verbes, contrairement aux classes fermées comme les prépositions, pronoms etc.).
Approche psycholinguistique – Le lexique mental :
Des unités seraient inscrites dans le code de notre mémoire. On parle de lexique interne, subjectif ou mental. Le lexique mental comporte toute l’information (phonologique, orthographique, morphologique, syntaxique, sémantique) concernant les mots connus de la langue.
Organisation du lexique et accès au lexique :
Deux problèmes distincts mais liés :
Il ne faut pas confondre la représentation lexicale (lexique) et celles des concepts liés à la connaissance du monde (encyclopédie). On essaie de dissocier des deux notions dans les études cognitives mais elles sont évidemment liées.
Qu’est ce que l’accès au lexique ?
Ce sont les opérations qui permettent d’associer des représentations sensorielles (stimuli) à une ou plusieurs représentations mentales correspondant à un mot de la langue. Dans une perspective cognitive, l’accès au lexique est défini de manière temporelle comme une étape fugitive mais essentielle du traitement. Avant l’accès au lexique, on parlera d’une étape pré lexicale à la différence d’une phase post lexicale ou post accès qui vient après l’accès au lexique.
Quelques méthodes d’étude :
Les tâches / techniques :
Il faut faire la différence entre « on line » (suivre le traitement en direct, dans le temps) et « off line » (rappel ou reconnaissance par exemple : résultat des opérations du sujet, en différé). Pour étudier l’accès au lexique, on utilise des tâches « on line ». Il y a deux grandes différences entre langage écrit et oral : l’écrit permet de donner l’ensemble du matériel en même temps alors que pour l’oral, l’information est donnée au fur et à mesure. De plus, la segmentation est apparente pour les mots écrits alors qu’elle est fait par le sujet pour les mots parlés.
Quelques tâches utilisées en visuel (langage écrit) :
La décision lexicale : on présente une suite de lettre au sujet qui doit déterminer s’il s’agit de mot ou de non-mots / pseudo-mots. Bien que pratique, cette méthode a deux inconvénients : on ne sait pas ce qu’identifie le sujet et l’aspect décisionnel introduit un biais post-lexical.
Le « naming » : le sujet doit lire à haute voix les mots qui lui sont présenté, avec le moins de latence possible. Cependant cette méthode nécessite plus de matériel pour évaluer le délai de réponse (clef vocale).
L’indentification en démasquage progressif : on présente des mots suivis immédiatement par des masques. A chaque présentation, on augmente le temps de présentation du mot et on diminue celui du masque jusqu’à ce que le sujet identifie le mot. Le sujet ne voit que le masque pendant un temps et voit progressivement apparaître le mot. L’inconvénient est qu’on ne peut pas étudier le paradigme d’amorçage avec cette tâche.
La détection (« monitoring ») : c’est une tâche assez peu utilisée. On demande généralement au sujet de détecter une anomalie. Les mots apparaissent les uns après les autres, très rapidement. On observe le phénomène de la cécité à la répétition c'est-à-dire que dans certains cas, les sujets ne détectent pas une répétition dans une phrase.
La dénomination de couleur (Stroop) : on utilise l’interférence Stroop comme mesure de la similitude sémantique.
La lecture avec enregistrement du mouvement des mots : lors de la lecture, il y a des saccades, des fixations et des régressions (refixation) des yeux et non une poursuite oculaire. Les mouvements oculaires reflètent la difficulté des tâches (fixations plus longues, saccades moins amples, régressions plus fréquentes). La difficulté varie en fonction de la nature de la tâche, la fréquence des mots dans la langue, l’ambiguïté lexicale, l’ordre des phrases relatives, la compréhension du texte.
Cependant, l’interprétation des mouvements des yeux n’est pas évidente car ceux-ci résultent non seulement de l’activité cognitive mais aussi des contraintes du système oculomoteur. La théorie de correspondance « eye-mind » (Just et Carpenter, 1980) prétendait que les mots étaient traités quand ils étaient fixés. Or on a des effets de débordement avec traitement avant (effet « preview ») et après (effet « spill over ») les fixations. Il n’y a donc pas de correspondance directe entre ce que fait l’œil et ce que fait l’esprit. De plus, il n’est pas évident de choisir et d’interpréter les différents indices (régressions, temps de fixation etc.).
Quelques tâches utilisées en auditif :
Le « gating » (présentation successive incrémentée) : on présente les premières millisecondes d’un mot en augmentant la longueur de la présentation jusqu’à ce que le sujet arrive à identifier le mot.
La détection : elle peut concerne les phonème, les syllabes, les mots, les rimes etc.
La décision lexicale : il s’agit de la même méthode qu’avec le langage écrit mais avec des stimuli sonores.
Le « shadowing » : le sujet doit répéter le plus rapidement possible ce qu’il entend.
Le paradigme d’amorçage :
Principe (Meyer et Schvaneveldt, 1971) :
Amorce (prime) |
Cible (target) |
Nurse |
Doctor |
Bread |
Doctor |
Le mot docteur sera plus facilement traité (en décision lexicale par exemple) lorsque l’amorce est liée (infirmière) : c’est l’effet d’amorçage ou prime effetc (différence de temps de traitement si le mot est précédé d’un mot lié ou non). Deux interprétations sont possibles : il peut y avoir facilitation par l’amorce liée ou inhibition par l’amorce non liée. Il faudrait donc une condition contrôle avec une amorce ni liée, ni non liée (de type : xxxx) et dans ce cas on constate les deux types d’effets. (De Groot, Thomassen et Hudson, 1982, ont utilisé le mot « blank » comme condition contrôle d’amorçage). Il y a différents types d’amorçage : sémantique, orthographique, phonologique et de répétition.
Amorçage intramodalité et amorçage intermodalités (Swinney, 1979) :
Dans l’amorçage intramodalité, l’amorce et la cible sont présentée dans la m^me modalité sensorielle contrairement à l’amorçage intermodalités. L’amorçage intramodalité a l’avantage de permettre de masquer l’amorce par la cible alors que l’amorçage intermodalité permet de présenter la cible avant la fin de présentation de l’amorce.
Paramètres temporels :
Le SOA (stimulus onset asynchrony) est le décalage temporel entre les débuts des stimuli et l’ISI (inter stimulus interval) est l’intervalle entre les stimuli. Lorsque ISI = 0, le SOA est confondu avec la durée de présentation de l’amorce. L’ISI est négatif si on présente la cible avant la fin de présentation de l’amorce.
Amorçage automatique et contrôlé (« stratégique ») :
Un stimulus peut être traité sans avoir été identifié. On parle d’amorçage automatique quand le sujet n’a pas conscience de l’amorce. Dans ce cas, il n’y a pas d’effet d’inhibition (seulement l’effet de facilitation) contrairement aux cas d’amorçage contrôlé où le sujet ayant identifié l’amorce pourra développer des attentes vis-à-vis de la cible à venir.
« L’amorçage rétroactif » :
Il pourrait y avoir un effet du traitement de la cible sur le traitement de l’amorce (pour des temps très courts) : c’est l’amorçage rétroactif. L’amorçage proactif est l’amorçage classique (effet de l’amorce sur la cible).
Quelques effets bien établis :
L’effet de la fréquence d’usage (Howes et Solomon, 1951) :
Les mots les plus fréquents dans la langue sont mieux traités que les moins fréquents. La fréquence d’usage est établie par des linguistes. On a aussi étudié les fréquences de bigrammes ou trigrammes (suite de 2 ou 3 lettres) dans la langue et on a constaté qu’à fréquence d’usage égale, un mot composé de bi ou trigrammes plus fréquents serait traités plus rapidement.
L’effet de la fréquence des voisins (Coltheart, Davelaar, Jonasson et Besner, 1977) :
On appelle voisin d’un mot, tous les autres mots de la même longueur partageant les mêmes lettres aux mêmes endroits, sauf une. En 1977, il n’a pas été montré d’effet du nombre de voisin. Mais le principe a été repris par Grainger, O’Reagan, Jacobs et Segui en 1989 en considérant cette fois la fréquence des voisins.
On distingue ainsi des mots qui n’ont aucun voisin plus fréquents, un voisin plus fréquent et plusieurs voisins plus fréquents ajoutés à ceux qui n’ont pas de voisins du tout. Il n’y a pas de différence entre l’absence de voisin et l’absence de voisins plus fréquents mais dès qu’il y a au moins un voisin plus fréquent que le mot, le temps de décision lexicale augmente. Ceci s’explique par le fait qu’il faut inhiber le ou les voisins plus fréquents pour traiter le mot. Les deux effets de fréquence d’usage et de fréquence d’usage des voisins sont totalement indépendants.
Les effets de contexte :
On distingue d’une part les effets d’amorçage qui sont liés seulement à une relation entre les mots mais d’autre part on a les effets « phrastiques » qui implique un lien entre l’ensemble de la phrase et la cible (sans lien avec un mot particulier de cette phrase). Par exemple : « Nous irons bientôt en Arizona » facilitera la cible « avion ».
Quelques points de repère pour comprendre les modèles :
Dimensions différenciant les modèles :
Il y a opposition entre des modèles autonomes et interactifs ; avec traitement parallèle ou sériel. De plus, on distingue des modèles actifs (activité de recherche par exemple) et passifs (activations seulement).
Quelques mots des logogènes (Morton, 1969) :
Les logogènes sont les représentations des mots. Le système des logogène est un compteur qui accumule les informations provenant aussi bien du stimulus que du système cognitif.
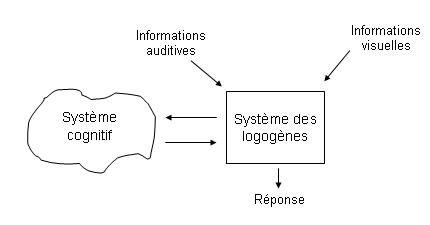
Le logogène est déclenché à partir d’un seuil d’activation qui engendre la reconnaissance ou la production du mot.
Ce modèle a été modifié pour le modèle suivant :
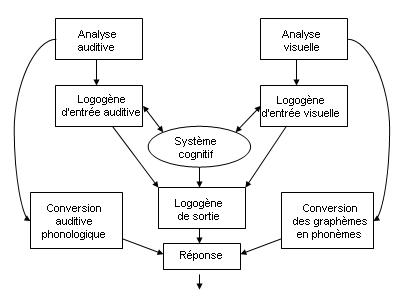
Ce modèle permet de faire la différence entre indentification et production des mots, mais aussi de rendre compte de certaines pathologies et introduit aussi la possibilité de lire ou répéter des non mots. Les effets de contexte favorisent l’activation des logogènes en augmentant leur activation au repos.
Mais ce modèle ne rend pas compte des effets inhibiteurs. Au niveau de la fréquence, Morton pense que ce n’est pas le niveau d’activation au repos qui varie mais le seuil d’activation qui est d’autant plus haut que le mot est rare.
Un exemple de recherche : le modèle de Forster (1976-1979) :
Ce modèle se traduit par la distinction entre le lexique même (appelé « fichier central ») et les voies d’accès à ce lexique (« access file ») comme les voies d’accès orthographiques, phonologiques, qui ne sont que des représentations des mots avec une seule modalité et qui sont des codes d’accès au lexique complet. (On peut aussi parler de la voie sémantique / syntaxique mais elle ne concerne pas l’identification mais la production de mot).
Les mots seraient classés dans des « casiers » de représentation partageant des propriétés formelles et classés par ordre de fréquence décroissante.
Forster a aussi proposé un modèle de compréhension globale du langage :
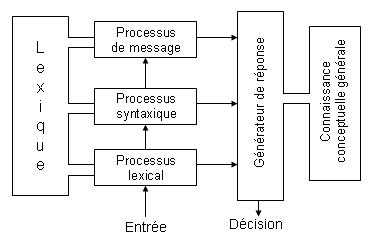
C’est un modèle où les processus sont autonomes et où le traitement est strictement sériel (lexical > syntaxique > message ; pour chaque mot). L’autonomie du processeur lexical se traduit par le fait qu’avec des mots ambigus, il y a d’abord accès exhaustif à tous les sens du mot avant la sélection.
Cependant, au niveau des effets de fréquence, ce modèle ne rend compte qu’en partie de l’effet d’existence de voisin et pas du tout de l’effet de la fréquence d’usage. Au niveau de l’effet du contexte, il n’y aurait pas de remise en cause de l’autonomie des processeurs car cet effet ne concerne que le lexique. Cependant, si on mélange l’ordre des mots, l’effet d’amorçage varie voire s’annule alors qu’il ne devrait pas varier selon ce modèle (car il ne concerne pas la syntaxe logiquement) : il y a donc remise en cause de ce modèle.
L’ancêtre des modèles connexionnistes : le modèle d’activation interaction de Mc.Clelland et Rumelhart (1981) :
Ce modèle a été fait pour rendre compte de l’effet de supériorité du mot : une lettre est plus rapidement traitée dans un mot que seule.
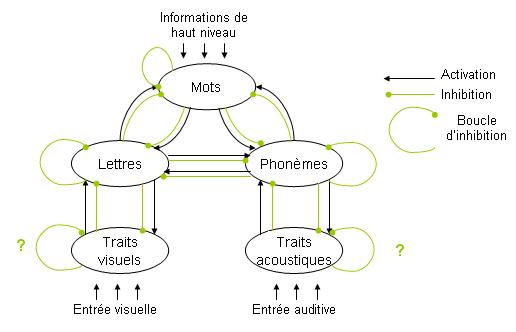
Chaque niveau correspond à un « nœud ». Le traitement dans ce modèle est parallèle, aussi bien au niveau temporel que spatial : toutes les lettres sont analysées en même temps à leur place dans le mot d’où les boucles d’inhibition (concurrence entre lettres etc.).
Modèle de « COHORT » :
Cf. Manuel.